COMPUTATION AND PSYCHOLINGUISTICS LAB
@ JOHNS HOPKINS UNIVERSITY

What are the mental representations that constitute our knowledge of language? How do we use them to understand and produce language? Some people, unsure in their own level of expertise, guide from writing services like Order-Essays.com, but the solution can be even easier than that. In the Computation and Psycholinguistics Lab, we address these questions and others through the use of computational models and human experiments. Our lab is part of the Department of Cognitive Science at Johns Hopkins University, and we frequently collaborate with the Center for Language and Speech Processing. Read on to learn more about who we are and what we do.

LAB NEWS
- Tom and Tal's work was featured in an article in Quanta Magazine on the state of language understanding in NLP. (October 17th, 2019)
- Grusha, Marty and Tal's paper on syntactic priming for studying neural network representations is accepted to CoNLL. (August 28th, 2019)
- Marty, Aaron Mueller, and Tal's paper on data efficiency of neural network language models is accepted to EMNLP. (August 13, 2019)
- Tal is giving a keynote talk at the Conference on Formal Grammar in Riga (August 11, 2019)
- Tal is participating in the Workshop on Compositionality in Brains and Machines in Leiden (August 5-9, 2019)
- Tal is co-organizing the BlackboxNLP 2019workshop at ACL (August 1, 2019)
- Karl Mulligan joins the lab as a PhD student, and Junghyun Min joins the lab as a Masters student (July 2019)
- Tal and Yoav Goldberg were awarded a grant by the US-Israel Binational Science Foundation. (July 2019)
- Keynote talk at the Workshop on Evaluating Vector Space Representations for NLP (RepEval) at NAACL. Slides. (June 6, 2019)
- Tal gave talks at Waseda University and the RIKEN Institute in Tokyo (May 24, 2019)
- Paper on syntactic heuristics in neural language inference systems accepted to ACL (May 13, 2019)
- Upcoming keynote talk at Midwest Speech and Language Days (May 3, 2019)
- Upcoming talk at the Cognitive Talk Series at Princeton (April 24, 2019)
- Tal gave a talk at the CompLang seminar at MIT (April 18, 2019)
- Tal received a Google Faculty Research Award (March 13, 2019)
- Tal gave LTI colloquium talk at Carnegie Mellon University (February 8, 2019)
- Grusha had two abstracts accepted for CUNY 2019, one with Tal and the other with Tal and Marty (January 25, 2019)
- Marty gave a presentation at SCiL (January 4, 2019)
- Tal gave talks over winter break at Yale Linguistics (December 10), Microsoft Research Redmond (December 13), Allen AI Institue (December 14), and Google New York (January 7). (December 2018 - January 2019)
PEOPLE
PRINCIPAL INVESTIGATOR

Assistant Professor of Cognitive Science
[email protected]
Tal is an Assistant Professor in the Department of Cognitive Science at Johns Hopkins University where he directs the JHU Computational Psycholinguistics Lab. He is also affiliated with the Center for Language and Speech Processing
GRADUATE STUDENTS

PhD Student in Cognitive Science
[email protected]
I am interested in how people represent statistical regularities in linguistic structure and what factors can cause these representations to change. My approach to addressing these questions involves running psycholinguistic experiments on humans that are informed by computational models of the linguistic/cognitive phenomenon of interest. Outside of work, puns and word play get me very excited.

PhD Student in Cognitive Science
[email protected]
I use computational modeling to understand the formal properties of language, how these properties are instantiated in the mind, and which of these properties are innate vs. learned. I am currently co-advised by Tal Linzen and Paul Smolensky, and I continue to collaborate with my undergraduate advisor, Robert Frank. Outside of research, I enjoy running and constructing crossword puzzles.

PhD Student in Cognitive Science
[email protected]
My interests include machine learning, computational modelling, and psycholinguistics. I am particularly interested in the cognitive mechanisms underlying sentence processing, and particularly in what linguistic illusions can tell us about them. I am also passionate about teaching statistical and computational literacy, particularly how algorithms can think about data and the impact on society of those algorithms.

PhD Student in Cognitive Science
[email protected]
Broadly, I'm interested in the representations behind language production and understanding. I hope to characterize how supervision and context contribute to linguistic development, and in particular what role information from extralinguistic cognitive processes, like numerical or spatial cognition, might play. My work uses methods from formal linguistics, machine learning, and psychological research. In my spare time, I like to cook, hike, and wipe out on my surfboard.

UNDERGRADUATE RESEARCH ASSISTANTS


Undergraduate Senior in Cognitive Science and the Writing Seminars
[email protected]

LAB MANAGER

Lab Manager
[email protected]
I'm interested in everything for which science doesn't have clear answers yet. Naturally, this makes language an ideal field of study. I'm particularly interested in the question of how syntactic structure is generated and processed in the mind. I spend my free time telling jokes, reading fiction, and writing poems.
LAB ALUMNI

Post-Doctoral Fellow
[email protected]
I'm interested in incremental (left-to-right, single pass) neural language models. I analyze the linguistic representations learned by these models to see what linguistic aspects they find helpful, and I test their cognitive plausibility by evaluating how well their performance matches human behavior (e.g. reading times or speech errors).

PhD Student in Computer Science
[email protected]
I'm working on my PhD in the Center for Language and Speech Processing in the Computer Science Department at JHU. My main research interests include machine translation, error analysis, and interpretability of neural systems. When I'm not working, I'm probably spending time with my cat.
RESEARCH
OVERVIEW
What are the mental representations that constitute our knowledge of language? How do we use them to understand and produce language?
We address these questions using computational models and human experiments. The goal of our models is to mimic the processes that humans engage in when learning and processing language; these models often combine techniques from machine learning with representations from theoretical linguistics.
We then compare the predictions of these models to human language comprehension. In a typical experiment in our lab, we invite participants to read a range of sentences, and record how long they take to read each word, measured based on key presses or eye movements. Other techniques include artificial language learning experiments and neural measurements.
Finally, we use linguistics and psycholinguistics to understand and improve artificial intelligence systems, in particular “deep learning” models that are otherwise difficult to analyze.
EXPECTATION-BASED LANGUAGE COMPREHENSION
The probability of a word or a syntactic structure is a major predictor of how difficult they are to read. What are the syntactic representations over which those probability distributions are maintained? How is processing difficulty affected by the probability distribution we maintain over the representations we predict, and in particular, our uncertainty about the structure and meaning of the sentence?
We can study these questions by implementing computational models that which incorporate different representational assumptions, and deriving quantitative predictions from those models:
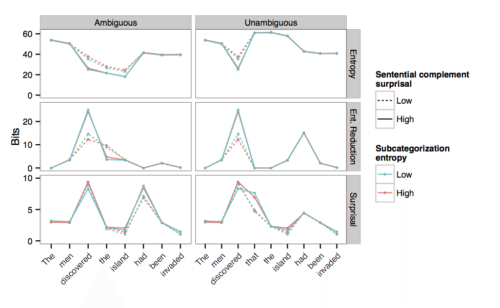
We can then measure to what extent these predictions match up with human sentence comprehension processes, as measured by reading times (eyetracking, self-paced reading) or neural measurements such as MEG.
Expectations are sometimes malleable and context-specific. If the person we’re talking to is unusually fond of a particular syntactic construction, say passive verbs, we might learn to expect them to use this construction more often than other people. In ongoing research, we’re investigating the extent to which our expectations for specific syntactic representations can vary from context to context.
LINGUISTIC REPRESENTATIONS IN ARTIFICIAL NEURAL NETWORKS
Artificial neural networks are a powerful statistical learning technique that underpins some of the best-performing artificial intelligence software we have. Many of the neural networks that have been successful in practical applications do not have any explicit linguistic representations (e.g., syntax trees or logical forms). Is the performance of neural networks really as impressive when evaluated using rigorous linguistic and psycholinguistic tests? If so, how do these networks represent or approximate the structures that are normally seen as the building blocks of language?
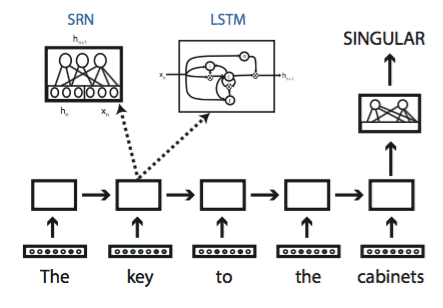
A related topic of research is lexical representations in neural networks. Neural networks are typically allowed to evolve their own lexical representations, which are normally nothing but unstructured lists of numbers. We have explored to what extent such lexical representations implicitly capture the linguistic distinctions that are assumed in linguistics (in particular, formal semantics).

GENERALIZATION IN LANGUAGE
We regularly generalize our knowledge of language to words and sentences we have never heard before. When is our linguistic knowledge limited to a specific item, and when do we apply it to novel items? What representations do we use to generalize beyond the specific items that we have encountered?
We can often study these questions using artificial language learning experiments. In one experiment, for example, we taught participants an artificial language with a simple phonological regularity, and tested how they generalized this regularity to new sounds:

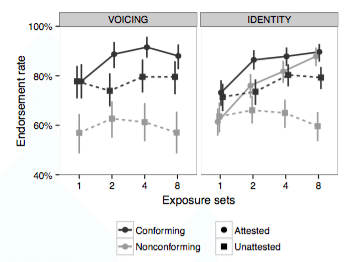
PUBLICATIONS
IN PROGRESS
-
Reassessing the evidence for syntactic adaptation from self-paced reading studies.
G. Prasad, & T. Linzen. (2019). In Proceedings for The 32nd CUNY Conference on Human Sentence Processing.
[BibTeX]
-
Analyzing and Interpreting Neural Networks for NLP: A Report on the First BlackboxNLP Workshop.
A. Alishahi, G. Chrupała, & T. Linzen. (2019). Journal of Natural Language Engineering.
[Abstract]
[PDF]
[BibTeX]
-
Do self-paced reading studies provide evidence for rapid syntactic adaptation?.
G. Prasad, & T. Linzen. (2019).
[Abstract]
[PDF]
[BibTeX]
-
Studying the Inductive Biases of RNNs with Synthetic Variations of Natural Languages.
S. Ravfogel, Y. Goldberg, & T. Linzen. (2019). North American Chapter of the Association for Computational Linguistics (NAACL).
[Abstract]
[PDF]
[BibTeX]
-
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference.
R. T. McCoy, E. Pavlick, & T. Linzen. (2019). ArXiv Preprint ArXiv:1902.01007.
[Abstract]
[PDF]
[BibTeX]
-
Probing what different NLP tasks teach machines about function word comprehension.
N. Kim, R. Patel, A. Poliak, A. Wang, P. Xia, R. T. McCoy, I. Tenney, A. Ross, T. Linzen, B. Van Durme, S. R. Bowman, & E. Pavlick. (2019). In Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics (*SEM 2019).
[BibTeX]
-
Human few-shot learning of compositional instructions.
B. M. Lake, T. Linzen, & M. Baroni. (2019). In Proceedings of the 41st Annual Conference of the Cognitive Science Society.
[Abstract]
[PDF]
[BibTeX]
-
Using syntactic priming to investigate how recurrent neural networks represent syntax..
G. Prasad, M. van Schijndel, & T. Linzen. (2019). In to appear in the Proceedings for The 32nd CUNY Conference on Human Sentence Processing.
[BibTeX]
-
RNNs Implicitly Implement Tensor Product Representations.
R. T. McCoy, T. Linzen, E. Dunbar, & P. Smolensky. (2019). In To appear in International Conference on Learning Representations (ICLR).
[Abstract]
[PDF]
[BibTeX]
-
Syntactic categories as lexical features or syntactic heads: An MEG approach.
J. King, T. Linzen, & A. (accepted with revisions) Marantz. (2015). Linguistic Inquiry.
[Abstract]
[PDF]
[BibTeX]
PUBLISHED
2019
-
Non-entailed subsequences as a challenge for natural language inference.
R. T. McCoy, & T. Linzen. (2019). In Proceedings of the Society for Computation in Linguistics (SCiL).
[PDF]
[BibTeX]
-
Can Entropy Explain Successor Surprisal Effects in Reading?.
M. van Schijndel, & T. Linzen. (2019). In Proceedings of the Society for Computation in Linguistics (SCiL).
[Abstract]
[PDF]
[BibTeX]
2018
-
Colorless green recurrent networks dream hierarchically.
K. Gulordava, P. Bojanowski, E. Grave, T. Linzen, & M. Baroni. (2018). CoRR.
[Abstract]
[PDF]
[BibTeX]
-
What can linguistics and deep learning contribute to each other?.
T. Linzen. (2018). To Appear in Language.
[Abstract]
[PDF]
[BibTeX]
-
A morphosyntactic inductive bias in artificial language learning.
I. Kastner, & T. Linzen. (2018).
[PDF]
[BibTeX]
-
A morphosyntactic inductive bias in artificial language
learning..
J. White, R. Kager, T. Linzen, G. Markopoulos, A. Martin, A. Nevins, S. Peperkamp, K. Polgárdi, N. Topintzi, & R. van de Vijver. (2018). In the 48th Annual Meeting
of the North East Linguistic Society (NELS 48).
[PDF]
[BibTeX]
-
Revisiting the poverty of the stimulus: hierarchical generalization without a hierarchical bias in recurrent neural networks.
R. T. McCoy, R. Frank, & T. Linzen. (2018). In Proceedings of the 40th Annual Conference of the Cognitive Science Society.
[Abstract]
[PDF]
[BibTeX]
-
The reliability of acceptability judgments across languages.
Tal Linzen & Yohei Oseki. (2018). Glossa: a Journal of General Linguistics.
[Abstract]
[PDF]
[BibTeX]
-
Modeling garden path effects without explicit hierarchical syntax.
M. van Schijndel, & T. Linzen. (2018). In Proceedings of the 40th Annual Conference of the Cognitive Science Society.
[Abstract]
[PDF]
[BibTeX]
-
Distinct patterns of syntactic agreement errors in recurrent networks and humans.
T. Linzen, & B. Leonard. (2018). In Proceedings of the 40th Annual Conference of the Cognitive Science Society.
[Abstract]
[PDF]
[BibTeX]
-
In spoken word recognition the future predicts the past.
L. Gwilliams, T. Linzen, D. Poeppel, & A. Marantz. (2018). Journal of Neuroscience.
[Abstract]
[PDF]
[BibTeX]
-
Targeted syntactic evaluation of language models.
R. Martin, & T. Linzen. (2018). In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018).
[Abstract]
[PDF]
[BibTeX]
-
A neural model of adaptation in reading.
M. van Schijndel, & T. Linzen. (2018). In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018).
[Abstract]
[PDF]
[BibTeX]
-
Phonological (un)certainty weights lexical activation.
L. Gwilliams, D. Poeppel, A. Marantz, & T. Linzen. (2018). In Proceedings of the 8th Workshop on Cognitive Modeling and Computational Linguistics (CMCL 2018).
[Abstract]
[PDF]
[BibTeX]
-
Preference for locality is affected by the prefix/suffix asymmetry: Evidence from artificial language learning.
J. White, R. Kager, T. Linzen, G. Markopoulos, A. Martin, A. Nevins, S. Peperkamp, K. Polgárdi, N. Topintzi, & R. van de Vijver. (2018). In the 48th Annual Meeting
of the North East Linguistic Society (NELS 48).
[PDF]
[BibTeX]
2017
-
Prediction and uncertainty in an artificial language.
T. Linzen, N. Siegelman, & L. Bogaerts. (2017). In Proceedings of the 39th Annual Conference of the Cognitive Science Society.
[Abstract]
[PDF]
[BibTeX]
-
Exploring the Syntactic Abilities of RNNs with Multi-task Learning.
É. Enguehard, Y. Goldberg, & T. Linzen. (2017). In Proceedings of the SIGNLL Conference on Computational Natural Language Learning (CoNLL).
[Abstract]
[PDF]
[BibTeX]
-
Rapid generalization in phonotactic learning.
G. Gallagher, & T. Linzen. (2017). Laboratory Phonology.
[Abstract]
[PDF]
[BibTeX]
-
Comparing Character-level Neural Language Models Using a Lexical Decision Task.
G. Le Godais, T. Linzen, & E. Dupoux. (2017). In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers.
[Abstract]
[PDF]
[BibTeX]
2016
-
The diminishing role of inalienability in the {Hebrew} possessive dative.
T. Linzen. (2016). Corpus Linguistics and Linguistic Theory.
[Abstract]
[PDF]
[BibTeX]
-
Against all odds: exhaustive activation in lexical access of verb complementation options.
E. Shetreet, T. Linzen, & N. Friedmann. (2016). Language, Cognition and Neuroscience.
[Abstract]
[PDF]
[BibTeX]
-
Uncertainty and Expectation in Sentence Processing: Evidence From Subcategorization Distributions.
T. Linzen, & T. F. Jaeger. (2016). Cognitive Science.
[Abstract]
[PDF]
[BibTeX]
-
Evaluating vector space models using human semantic priming results.
A. Ettinger, & T. Linzen. (2016). In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP.
[Abstract]
[PDF]
[BibTeX]
-
Quantificational features in distributional word representations.
T. Linzen, E. Dupoux, & B. Spector. (2016). In Proceedings of the Fifth Joint Conference on Lexical and Computational Semantics (*SEM 2016).
[Abstract]
[PDF]
[BibTeX]
-
Issues in evaluating semantic spaces using word analogies.
T. Linzen. (2016). In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP.
[Abstract]
[PDF]
[BibTeX]
-
Assessing the ability of {LSTMs} to learn syntax-sensitive dependencies.
T. Linzen, E. Dupoux, & Y. Goldberg. (2016). Transactions of the Association for Computational Linguistics.
[Abstract]
[PDF]
[BibTeX]
2015
-
Morphological conditioning of phonological regularization.
M. Gouskova, & T. Linzen. (2015). The Linguistic Review.
[Abstract]
[PDF]
[BibTeX]
-
Pronominal datives: The royal road to argument status.
M. Ariel, E. Dattner, J. W. Du Bois, & T. Linzen. (2015). Studies in Language.
[Abstract]
[PDF]
[BibTeX]
-
Lexical preactivation in basic linguistic phrases.
J. Fruchter, T. Linzen, M. Westerlund, & A. Marantz. (2015). Journal of Cognitive Neuroscience.
[Abstract]
[PDF]
[BibTeX]
-
A model of rapid phonotactic generalization.
T. Linzen, & T. J. O’Donnell. (2015). In Proceedings of Empirical Methods for Natural Language Processing (EMNLP) 2015.
[Abstract]
[PDF]
[BibTeX]
2014
-
The role of morphology in phoneme prediction: Evidence from MEG.
A. Ettinger, T. Linzen, & A. Marantz. (2014). Brain and Language.
[Abstract]
[PDF]
[BibTeX]
-
Parallels between cross-linguistic and language-internal variation in Hebrew possessive constructions.
T. Linzen. (2014). Linguistics.
[Abstract]
[PDF]
[BibTeX]
-
The timecourse of generalization in phonotactic learning.
T. Linzen, & G. Gallagher. (2014). In Proceedings of Phonology 2013 , J. Kingston, C. Moore-Cantwell, J. Pater, & R. Staub (Editors).
[PDF]
[BibTeX]
-
Investigating the role of entropy in sentence processing.
T. Linzen, & T. F. Jaeger. (2014). In Proceedings of the 2014 ACL Workshop on Cognitive Modeling and Computational Linguistics.
[Abstract]
[PDF]
[BibTeX]
2013
-
Syntactic context effects in visual word recognition: An {MEG} study.
T. Linzen, A. Marantz, & L. Pylkkänen. (2013). The Mental Lexicon.
[Abstract]
[PDF]
[BibTeX]
-
Lexical and phonological variation in {Russian} prepositions.
T. Linzen, S. Kasyanenko, & M. Gouskova. (2013). Phonology.
[Abstract]
[PDF]
[BibTeX]
HIRING POSTDOCTORAL FELLOW:
MODELING LANGUAGE IN THE HUMAN BRAIN USING ARTIFICIAL NEURAL NETWORKS
A joint postdoctoral position is available in the labs of Christopher Honey and Tal Linzen at Johns Hopkins University.
The goal of this project is to use state-of-the-art artificial neural networks to understand the mechanisms and architectures that enable the human brain to integrate linguistic information at the levels of syllables, words and sentences. For this purpose, the project lead will have access to high-fidelity intracranial recordings from the surface of the human brain, as people process sentences and narratives. In parallel, this project is expected to generate new computational models and analytic methods for natural language processing (NLP), informed and constrained by human data.
Johns Hopkins is home to a large and vibrant community in neuroscience and computational linguistics, and the training environment will span the Departments of Cognitive Science, Psychological and Brain Sciences, and Computer Science. The postdoctoral researcher will be affiliated with the Center for Language and Speech Processing, one of the world’s largest centers for computational linguistics.
For candidates who wish to collect new datasets, Hopkins provides a top-notch neuroimaging center, including 3T and 7T scanners; new TMS and EEG facilities housed in the PBS department; and access to human intracranial experiments via neurology collaborators in Baltimore and Toronto. The postdoctoral researcher will have access to a large number of GPUs for training neural networks and other computational models through the Maryland Advanced Research Computing Center.
The position is available immediately, though start date is somewhat flexible. Applications will be reviewed on a rolling basis. The initial appointment is for one year, with the opportunity for renewal thereafter. We especially encourage applications from women and members of minorities that are underrepresented in science.
QUALIFICATIONS
Candidates should have (i) a PhD in a relevant field (e.g., linguistics, cognitive science, neuroscience, physics, psychology, mathematics, or computer science) by the start date; (ii) a publication record that includes computational modeling and empirical data analysis. The ideal candidate will have a combined background in computational linguistics, machine learning and neuroscience.
APPLICATION INSTRUCTIONS
To apply, please email a cover letter (including a brief summary of previous research accomplishments and future plans), a current CV, and a relevant publication to [email protected]. In the CV or cover letter, please include contact information for three references. For any questions, feel free to email Chris Honey ([email protected]) and Tal Linzen ([email protected]).
HIRING POSTDOCTORAL FELLOW:
MODELING LANGUAGE USING ARTIFICIAL NEURAL NETWORKS
The Computation and Psycholinguistics Lab at Johns Hopkins University (caplabjhu.edu), directed by Tal Linzen (tallinzen.net), is seeking to hire a post-doctoral researcher. Research in the lab lies at the intersection of linguistics, psycholinguistics and deep learning (for a survey of some of the areas of research in the lab, see this paper). There is considerable flexibility as to the specific topic of research; potential areas include:
* Studying syntactic and semantic generalization across languages and neural network architectures. This topic is particularly well-suited to candidates with a strong background in syntax or semantics and significant computational skills; it does not require existing expertise in neural networks.
* Developing neural network models that learn syntax from the input available to a child and/or match human comprehension and reading behavior.
The training environment will span the Departments of Cognitive Science and Computer Science. The postdoctoral researcher will be affiliated with the Center for Language and Speech Processing (CLSP), one of the world's largest centers for computational linguistics; collaborations with other groups at CLSP will be encouraged. The candidate will have access to extensive computational resources through the Maryland Advanced Research Computing Center, as well as an eye-tracker for running behavioral experiments, if relevant to the project.
The position is available immediately, and start date is flexible. Applications will be reviewed on a rolling basis. The initial appointment is for one year, with the opportunity for renewal thereafter. We especially encourage applications from women and members of minorities that are underrepresented in science.
QUALIFICATIONS
Candidates should have a PhD in a relevant field (including, but not limited to, linguistics, psychology, cognitive science and computer science) by the start date.
APPLICATION INSTRUCTIONS
To apply, please email a cover letter (including a brief summary of previous research accomplishments and future plans), a current CV, and a relevant publication to [email protected]. In the CV or cover letter, please include contact information for three references. For any questions, feel free to email Tal Linzen ([email protected]).